Integrated Resource Management for Virtualized Embedded Systems
Kishore Ramachandran
Georgia Tech PI: Kishore Ramachandran
Students: Dushmanta Mohapatra, Hyojun Kim
Samsung Technical POC: Dr. Sang-bum Suh, Junghyun Yoo
1. Project Goals
- The primary objective of this project is to design and implement mechanisms for efficient resource management in virtualized embedded devices.
2. Project Details
Background
System virtualization has been very successful for high end server-class machines because it provides benefits such as consolidation, increased utilization, rapid provisioning, dynamic fault tolerance against software failures through rapid bootstrapping or rebooting, and hardware fault tolerance through migration of a virtual machine to different hardware.
Until now virtualization techniques have hardly been used for mobile embedded devices even though it has many potential benefits for mobile devices. For instance, system virtualization would allow applications developed on diverse platforms to run on a generic platform thus increasing the extensibility of mobile devices without compromising the security for trusted applications. Further, it would also allow seamless user mobility across platforms with migration functionality. The increasing processing power and storage capability of the mobile devices coupled with the trend of mobile device OS vendors making their systems open points to a healthy virtualization based ecosystem for mobile devices.
System Architecture
To use virtualization technology for mobile embedded devices, we need to minimize various virtualization overheads. Especially, memory resource management is a very critical problem for resource-constrained embedded systems. We have two target goals
- Dynamic Resource (memory) Partitioning among guest OSes. If there is memory remaining unutilized (/improperly utilized) and there is a need for more memory in some system then there should be fast and low overhead mechanisms to reallocate memory to the needy VMs
- Efficient memory sharing among guest OSes by keeping single copy of pages with common content.
Memory has always been a scarce resource in virtualized environments. The need for memory and its efficient utilization are much more pronounced in the case of embedded devices (as compared to server environments). As such, the primary goal of the project has been to achieve dynamic memory resource allocation in a virtualized environment targeted for embedded devices.
In the normal mode of operation, the OS kernel is entrusted with efficient multiplexing of the amount of available physical memory among the competing processes. Managing a fixed amount of memory (RAM) optimally is a long-solved problem in the Linux kernel. Managing RAM optimally in a virtual environment, however, is still a challenging problem for to the following reasons:
- Each guest kernel focuses solely on optimizing its entire fixed RAM allocation oblivious to the needs of other guests.
- Very little information is exposed to the virtual machine manager (VMM) to enable the VMM to decide if one guest needs RAM more than another guest.
Previous research has produced mechanisms like ballooning and memory-hotplugging,which allow memory to be taken from a guest domain that is having un-utilized memory to a domain which needs more memory. But when more than two domains are running, there is an issue of choosing the domain from which to take memory. It is because of the inherent hardness in estimating the actual memory needs of various domains at the hypervisor level. The Collaborative Memory Management (CMM) project at IBM attempted to solve this issue by devising a mechanism to transfer memory related information from each guest into the hypervisor, but the resulting architecture was deemed a bit complex for mainstream usage.
Transcendental Memory (T-Mem) is an effort directed at solving the similar problem of efficient memory allocation among a group of competing domains. In the original T-Mem approach, underutilized RAM from each domain and RAM unassigned to any domain is collected into a central pool and an indirect access to this central pool is provided by the VMM through a page-copy based interface. The modifications required to Linux kernel (to become compatible with the T-Mem architecture) is relatively small and the performance benefit achieved (in terms of reduced I/O cost and less latency involved in memory transfer) more than compensates for the development effort involved.
T-Mem aims to provide a mechanism by which memory could be treated as a renewable resource. As has already been explained, this is achieved by creating a central memory pool and allowing domains to use them in a controlled manner. If there is space available in the central pool and a domain needs more memory for its workload, it can ask the hypervisor to put some pages into this global pool. This saves the guest from costly disk/swap I/O as the pages are available in memory. When another domain needs memory, some of the pages in the central pool that are being used for storing content of other domains could be freed. From the perspective of an operating system, T-Mem is a fast pseudo-RAM of indeterminate and varying size that is useful primarily when real RAM is in short supply and is accessible only via a somewhat quirky copy-based interface.
Figure 1 shows the T-MEM usage model.
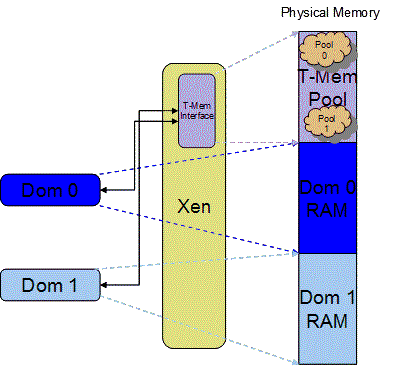
Figure 1. T-MEM Usage Model
Each domain has direct access to the RAM allocated to it. In addition to that, each domain also has a page-copy based indirect access to the global pool of memory allocated to T-Mem. Domains (/Virtual Machines) can create pools in this T-Mem pool and can use them to store memory pages.
T-MEM in Xen-ARM
In this project, we adapt T-Mem to work in Xen-ARM. The platform we use is nVidia’s Tegra board. Currently available Xen-ARM version is 3.0.1, while the oldest T-Mem is for Xen 3.3.1. To enable T-Mem on Xen-ARM, we had to solve Xen version, 32-bit architecture, and ARM architecture related issues. Following are some of the details involved in the porting task.
- T-Mem sources: Even though T-Mem is officially included into Xen 4.0, it is not a good idea to use those sources for Xen-ARM because Xen-ARM is still based on Xen 3.0.1 version. We decided to use T-Mem sources released for Xen 3.3.1 to minimize the version mismatch issues.
- 32 bit architecture issue: The hardest problem of T-Mem porting task is that T-Mem has been designed mainly for 64-bit architecture machines. 32-bit machine has only 4GB address space, and most of that space is used for guest OS. Xen heap and dom heap sizes are small due to the cramped address space. Because T-Mem is designed to use dom heap, without adequate modifications, the T-Mem's memory pool size is limited only to few mega bytes. To solve this problem, we separated T-Mem data page frames from memory used for storing T-Mem data structures, and modified T-Mem memory allocator to use page frames without address space allocation.
- Linux Patch: To use T-Mem, Linux kernel needs to be modified. Fortunately, there is an available T-Mem patch for Linux-2.6.29, and relatively small amount of modifications were required (primarily related with the T-Mem specific hyper-calls).
- T-Mem statistics in /proc file-system: To easily access T-Mem statistics, we use /proc interface. We create /proc/T-Meminfo file virtually, and provide T-Mem internal statistics to Linux.
Snapshot of Performance Results
We have conducted micro-measurements of the T-MEM operations such as put-page and get-page. Table below shows a comparison of these operations in comparison to storage devices. In mobile devices, a MicroSDHC card is often used as swap device, and as we can see from the result, T-Mem is 15,462 times faster than measured MicroSDHC card.
Storage Device |
Possible Swap Op. / second |
Comparison with T-Mem |
T-Mem |
47846.9 |
- |
2.5inch 5400RPM HDD 80GB |
63.8 |
X 750 slower |
SAMSUNG SLC SSD 64GB |
146.6 |
X 326 slower |
Kingston MLC SSD 64GB |
52.4 |
X 914 slower |
USB Memory Stick 2GB |
3.7 |
X13,015 slower |
Kingston MicroSDHC 16GB |
3.1 |
x15,462 slower |
We have also developed demonstration application to showcase the working of T-MEM as memory pressure builds up in different domains. The application uses two client programs running on the Tegra board making dynamic memory requests as dictated by a server program running on a network connected Linux box. The following snapshot represents the results generated in a scenario where the workload is generated statically at the server side and the client side memory allocation happens incrementally.
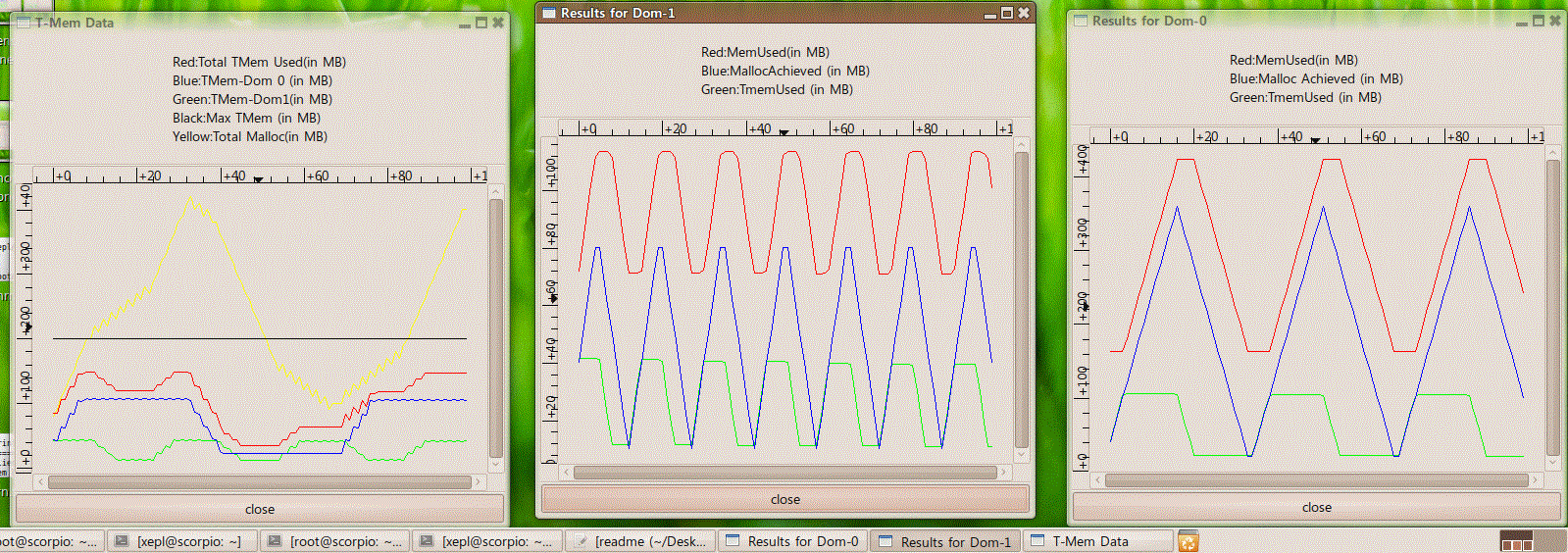
This goal of this project was to implement dynamic memory resource management in a virtualized embedded system. Using nVidia’s Tegra board and Xen-ARM distribution from Samsung, we have successfully implemented transcendental memory for use by guest operating systems executing on top of Xen-ARM to deal with dynamic memory pressure. We have conducted preliminary performance measurements of our implementation to validate the utility of transcendental memory as an intermediate level in the memory hierarchy between RAM and stable storage. Complete details can be found in the final project report delivered to Samsung.
3. Research Artifacts
- Sang-bum Suh, Xiang Song, Jatin Kumar, Dushmanta Mohapatra, Umakishore Ramachandran, Jung-Hyun Yoo, and Ilpyung Park, 2008. “Chameleon: A Capability Adaptation System for Interface Virtualization,” MobiVirt 2008, Workshop on Virtualization in Mobile Computing Held in conjunction with MobiSys 2008, Breckenridge, Colorado, USA, June 17, 2008.
- Xiang Song, Dushmanta Mohapatra, Umakishore Ramachandran, Sang-bum Suh, Junghyun Yoo, 2009. “Capability Adaptation System for Interface Virtualization,” Invention Disclosure filed jointly by Georgia Tech and Samsung.
- Dushmanta Mohapatra, Umakishore Ramachandran, Xiang Song, Jatin Kumar, Sang-bum Suh, “Virtualized Approach Towards Achieving Seamless Mobility,” School of Computer Science, Technical Report GT-CS-10-13, Georgia Tech, 2010.
- Umakishore Ramachandran, Dushmanta Mohapatra, Hyojun Kim, “Memory Resource Management
In Virtualized Embedded Devices,” Final Project Report, November 23, 2010.